
Quand on se dit qu'il faut s'attaquer à la dette c'est qu'il est souvent déjà trop tard. Voici une stratégie qui m'a aidé, et qui servira que votre projet soit sous l'eau ou en bonne santé.
J'ai commencé à parler d'un modèle que j'utilise sur ma mission actuelle, et qui est grosso modo une forme plus explicite de la façon dont je pratique la priorisation des "sujets techniques", notamment l'infâme "dette technique".
TL;DR: passez à la partie suivante.
Rétrospectivement, le concept de dette ne m'a réellement servi que lors de discussions vis à vis de projets inventés de toutes pièces pour se convaincre les uns les autres de la façon dont gérer ce qu'il se cachait sous le concept. Autant dire, on avait besoin d'un concept pour résoudre un problème inventé, et pouvoir se féliciter quand l'univers factice tenait debout tout seul dans la logique qu'on avait pu se partager.
En revanche, quand il s'agissait de parler de ce qui se cache réellement derrière ce concept de dette, la métaphore m'a finalement le plus souvent desservie. Combien de projets en bonne santé avez-vous rencontrés qui ont dû investir dans une étude, une réflexion profonde, et des indicateurs pour gérer leur dette ? Et combien de fois avez-vous vu ces mêmes choses pour des projets dont on se disait que la dette était le problème qui faisait que le système était en mauvaise santé ? D'expérience, et des discussions que j'ai eu avec d'autres du domaine, proportionnellement bien plus dans le second cas que dans le premier. La question de la dette ne se pose pas dans un projet qu'on sait maintenir, en revanche elle se pose dans un projet qu'on ne sait pas maintenir. Et c'est là que la métaphore de la dette est contre productive, car elle nous fait croire qu'il suffit de "régler la dette", alors qu'en réalité on devrait apprendre à maintenir le projet.
La métaphore la plus proche que j'ai pu trouver pour mieux illustrer cette activité à gérer est celle de "maintenance load", ou charge de maintenance, que j'ai pu lire dans l'article "Quantifying Technical Debt" de Chelsea Troy. En gros, avec mes propres mots, la charge de maintenance c'est l'effort investi à faire autre chose que faire évoluer le système pour le bénéfice direct des utilisateurs. Quelques exemples : corriger un bug, investiguer un incident, faire des rollbacks, mettre à jour des dépendances, intégrer du code entre branches, etc. Plus on passe de temps sur la charge de maintenance, moins on a de temps pour fournir de nouvelles fonctionnalités. Hors, comme l'indique très bien l'article cité plus haut, plus on ajoute de fonctionnalités, plus on dégrade le système. Et forcément, plus il est dégradé, plus il est difficile de le faire évoluer, que ce soit pour des fonctionnalités ou de l'amélioration technique. On voit alors que la dette n'est pas un problème en soi, mais un symptôme d'un problème plus profond : on ne sait pas maintenir le système. Régler la dette revient donc à régler les symptômes, et non la cause. Et comme tout symptôme, il peut revenir, et il reviendra tant qu'on ne s'attaquera pas à la cause : savoir maintenir le système.
L'avantage de cette métaphore c'est que lorsqu'il s'agit de savoir par quoi commencer, il devient facile de comprendre que le but sera de réduire le maximum de charge de maintenance avec le moins d'effort possible. Et non de refactorer du code parce qu'on ne le trouve "pas beau", ou parce qu'il ne correspond pas aux "bonnes pratiques" du marché.
Récemment, un ami me parlait de la volonté de sa hiérarchie de s'attaquer à la dette, et comme j'avais un outil sous la main qui m'aidait à traiter ces sujets en continu et avoir une stratégie pour les prioriser, je lui ai proposé de lui partager. La suite est peu ou prou ce que j'ai pu lui dire.
Les gens qui entretiennent le code (appli, d'infra, peu importe) savent souvent là où ça va mal, donc le principe c'est de leur faire dumper tout ce qu'ils verraient à améliorer dans leur quotidien. Le mieux c'est de faire ça sur un board / tableau blanc pour qu'ils dumpent leurs tickets / post-it chacun dans leur coin. Tant pis pour les répétitions, ce sera même un indicateur de ce qui motive / intéresse / touche le plus l'équipe.
Une fois les tickets dumpés, il risque d'y avoir de tout. On cherche à faire ressortir les axes d'amélioration tech, mais sans nier le reste qui a été pondu car ça a aussi de la valeur. Donc pour commencer chaque personne va présenter ses tickets. Les gens discutent pour bien comprendre de quoi il s'agit, et on regroupe les tickets au fur et à mesure pour les catégoriser.
Ce qui n'est pas de l'amélio technique est à mettre dans des catégories qui serviront en dehors du cadran. Deux exemples :
Le reste, c'est sûrement de l'amélio tech, et c'est à l'équipe de décider ce qui est prioritaire. Et voilà comment :
Une fois tout présenté, pour aider l'équipe à prioriser, on va utiliser un cadran avec deux axes
Si on a peu de tickets / participants, le mieux est encore de discuter de chaque ticket et de le placer sur le cadran. Si on a beaucoup de tickets / participants, on peut utiliser le même principe que l'extreme quotation : en gros chacun prend des tickets au hasard, et sans discuter avec les autres les posent sur le cadran. Quand on a plus de tickets, on regarde ce qui a été posé, et si on est pas d'accord avec le positionnement d'un ticket on le dit pour en parler avec l'équipe. C'est très rapide car on ne parle que de ce qui n'est pas évident.
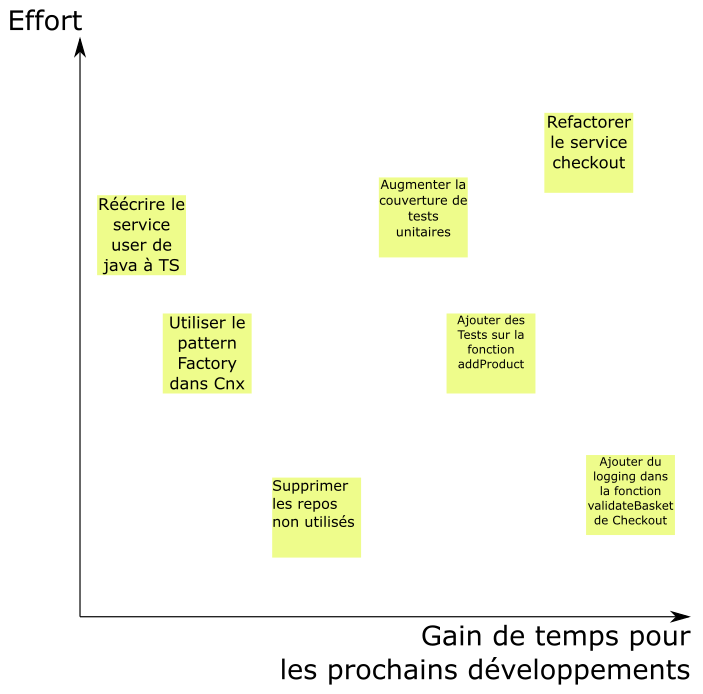
Un exemple de cadran avec des tickets
Une fois ces tickets placés, on trace les impitoyables lignes de séparation du cadran.
Dans les équipes les plus avancées (et je parle bien en tant qu'équipe et non de personnes), la taille est quelque chose de plus facilement appréhendable et estimable, et on peut donc définir des tailles de tâches en heures / jours / points / whatever, et placer les lignes en fonction de ça. Si vous prenez habituellement 20% à 30% d'un temps de sprint pour de l'amélioration technique, avoir une estimation plus évidente permet de rendre la capacité de production de fonctionnalités de l'équipe plus prédictible.
Dans le cas où l'équipe n'en est pas à ce niveau et qu'elle court après les problèmes l'enjeu est d'abord de stabiliser les choses et de se donner les capacités de pouvoir découper les tâches tech (des prérequis de la prédictibilité). Par exemple en découplant certains morceaux pour limiter les effets tunnel en cas de modification. Et moins d'effet tunnel signifie plus d'espace durant les sprints pour de la fonctionnalité et un espace plus prédictible pour améliorer la technique (un début de cercle vertueux donc).
Dans ces cas là donc je place les lignes arbitrairement, ici je les aligne pile sur les milieux des axes, car le placement des tickets est fait relativement les uns aux autres. Ce qui permet donc à l'équipe de prendre de définir des tâches comme "petites" relativement à ce qu'elle est capable de faire de plus petit à ce jour.
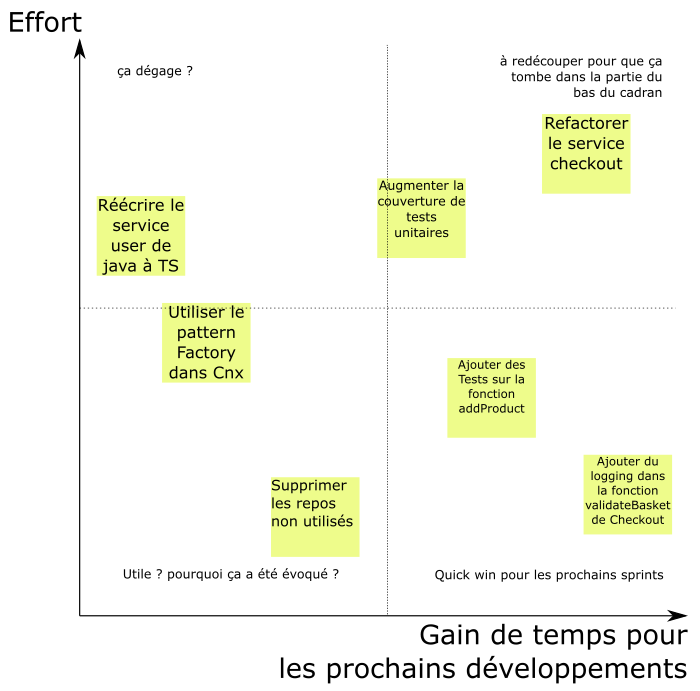
Le cadran avec les lignes pour classer les tickets, et des hints sur quoi faire de chaque zone
En somme :
Le contenu du cadran va vieillir, mais contrairement à un backlog de dette, ce n'est pas grave, on peut même jeter ce qui ne bouge jamais des cadrans pas immédiatement activables. Tout ce qui compte c'est de trouver des tickets qui tombent dans le cadran en bas à droite, et de les traiter.
Le mieux est de réévaluer ce qu'il y a dans le cadran durant les rétrospectives techniques (1 à 2 fois par sprint le plus souvent suffisent).
Si par le plus grand des hasards vous vous retrouvez avec trop de tickets dans cette zone (déjà se demander si on a bien évalué leur position), une solution est de se demander ce qui va arriver fonctionnellement dans les prochains sprints et de prendre les tickets qui aideront à développer ces fonctionnalités plus efficacement ou simplement.
L'avantage, c'est que c'est transparent pour tout le monde, et facile à communiquer aux stakeholders, et donc facile de justifier pourquoi cette tâche est faite, et montrer qu'on se soucie de notre capacité à pouvoir continuer à "livrer de la valeur".

